result = [ expr for val in collection if condition ]
普通推导式
1 2 3 4 5
strings = ['a', 'b', 'c', 'as', 'bat', 'car', 'dove', 'python', 'love', 'pythove'] l = [val for val in strings if'ove'in val] d = {key:val for val, key inenumerate(strings) if'ove'in key} s = {val for val in strings if'ove'in val} print('list is {0} \ndict is {1} \nset is {2}'.format(l, d, s))
list is \['dove', 'love', 'pythove']
dict is \{'dove': 6, 'love': 8, 'pythove': 9}
set is \{'pythove', 'dove', 'love'}
嵌套推导式
1 2
tuples = [(1,2,3),(4,5,6),(7,8,9)] [val2 for val1 in tuples for val2 in val1]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
1
[[val2 for val2 in val1] for val1 in tuples ]
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
函数
def function( vars ) : ... return expr : 一般函数 function = lambda vars : expr : lambda 函数
一般函数
1 2 3 4 5 6
deff(x, y, z=2): if z > 1: return z*(x+y) else: return z*(x-y) f(5, 4, 1), f(5, 4)
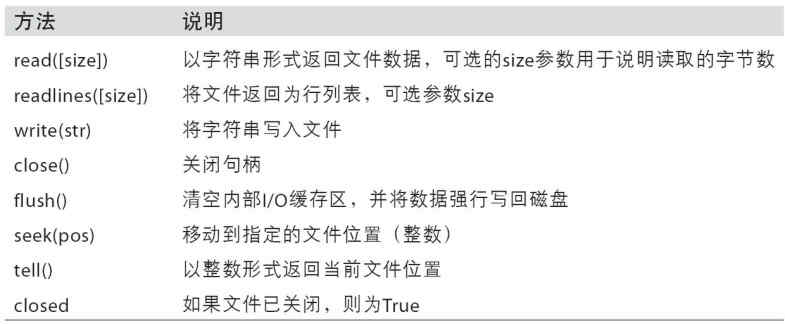
f.tell( ), f.seek( position ), f.read( size ), f.readlines( hint )
1 2 3 4 5 6 7
withopen(path) as f: print(f.tell()) # 从0开始 l = f.read(9) # 从当前位置向前读取9个字符 print(f.tell()) #读取的字节数 f.seek(8) #定位文件中的位置,单位:字节 print(f.tell()) print(f.read(5))
0
18
8
我如果爱
写入
f.write( text ), f.writelines( lines )
1 2 3 4 5 6 7 8 9
path_out = os.getcwd() + '\\out.txt' withopen(path_out, mode='w') as f_out: f_in = open(path) f_out.write('ZHI XIANG SHU\n') f_out.writelines(x for x in f_in) f_in.close() withopen(path_out) as f: lines = f.readlines(14) # 从当前位置向前读到第14个字符所在的行 print(lines)
['ZHI XIANG SHU\n', '致橡树:\n']
字符模式与字节模式
字符模式(unicode):' ...... ' 字节模式(encode):b' ...... '
1 2 3 4 5 6 7 8 9 10 11 12 13
withopen(path) as f_str: data_str = f_str.read(10) ##向前读10个字符 withopen(path, 'rb') as f_gbk: data_gbk = f_gbk.read(10) ##向前读10个字节 print(data_str) print(data_str.encode('gbk')) print(data_gbk)
path_out = os.getcwd() + '\\out_utf8.txt' withopen(path_out, mode='w', encoding='utf8') as f_out: f_in = open(path) f_out.writelines(x for x in f_in) f_in.close()